
Expérience et expertise
15 ans d'expérience dans la conception web
Approche sur-mesure
Solutions sur mesure correspondant à vos besoins
Ergonomie et rapidité
Nos sites sont conçus pour être rapides et pratiques
Sites et serveurs sécurisés
Nous travaillons avec des hébergeurs fiables
Votre succès en ligne grâce à des solutions éprouvées
Réussir sur le web ne s’improvise pas : sans préparation, sans plan d’action, la mise en ligne d’un site ne sert à rien.
Créer un site qui réalise du trafic, ça n’est pas si compliqué quand on a un cadre de travail solide et un rêve à poursuivre : avec les bonnes méthodes, les bons outils, une analyse rigoureuse et un plan d’action, tout est possible. La réussite sur le web n’est qu’une question de motivation et de temps !
Charles Annoni - Chef de projet

Nos services en communication digitale à Caen
Un service de haute qualité pour tous
Nous sommes tributaires de nos clients et notre priorité, c’est de vous fournir les services que vous méritez.
Des horaires de travail extensibles, 7J/7
Nous pouvons intervenir 24h / 24, 7 jours/7, si vos conditions de production le nécessite.
Une agence web professionnelle
Notre expérience nous permet de vous conseiller et de vous orienter vers les meilleures solutions.
Des créations sur-mesure, à votre image
Nous travaillons sur-mesure, pour vous proposer un site adapté à votre niche, et à votre société.
Les meilleures technologies du marché
Nous effectuons une veille constantes pour n’utiliser que des technologies adaptés, robustes et fiables.
Votre intérêt avant toute autre chose
Notre priorité, c’est de vous permettre de vous développer : on ne vous vendra jamais quelque chose d’inutile.
Nos prestations en matière de création de site, webmarketing et webdesign



Ils travaillent avec nous et nous font confiance

Charles est le meilleur spécialiste de la région caennaise en e-commerce. A des prix défiants toutes concurrence.
Sylvain Vandewalle Sinay
Je recommande fortement cette agence ! Tout le travail effectué pour nous a été réalisé rapidement, et avec beaucoup de professionalisme.
Jérome de la Casinière La Casinière
Depuis un an nous avons confié notre site et tout le suivi à cette agence. Travail sérieux, méthodique, nos résultats sont en constante augmentation.
Marie-France Gras AC Communication
Excellent formateur SEO, réunissant l’expertise et le sens de la pédagogie.
Marie Mure Ravaud Snap Inc
Charles Annoni est disponible et possède une énergie remarquable. Je le recommande à ceux qui veulent améliorer leur visibilité sur Internet.
Charles Dévé Crédit MutuelVous pouvez également demander une consultation en ligne, en visioconférence


Quelques une de nos dernières création de site internet
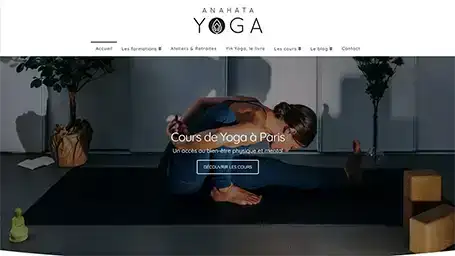
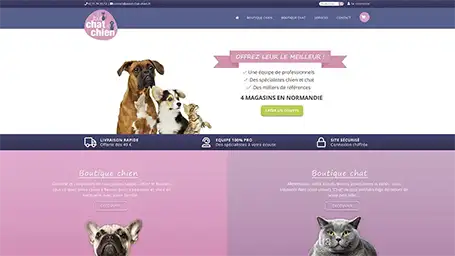
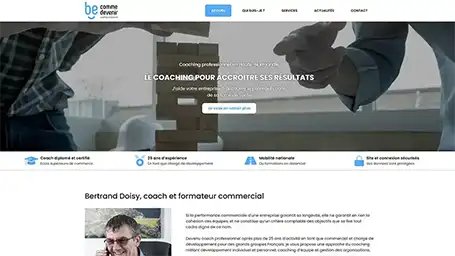
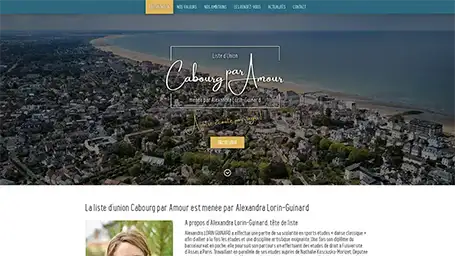
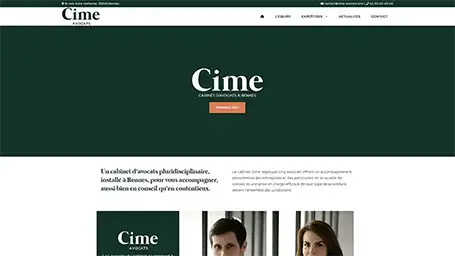
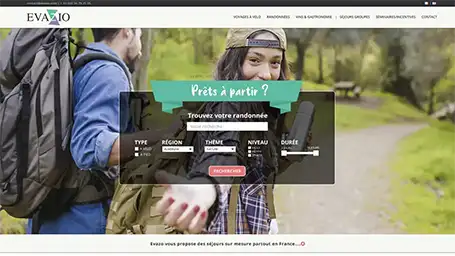
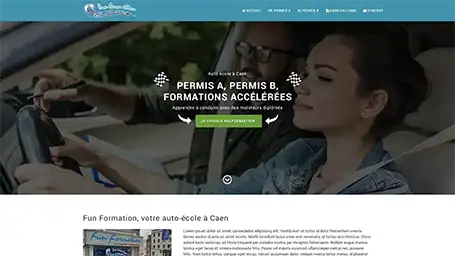
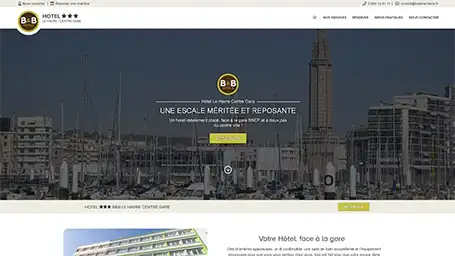
Réponses aux questions fréquentes
R : Tout dépend de votre projet ! Le coût d’une création de site internet peut aller de quelques centaines à plusieurs milliers d’euros. Cela dépend de divers facteurs tels que le nombre de pages, les fonctionnalités souhaitées, les technologies utilisées et le temps de travail nécessaire pour mener à bien votre projet.
En effet, plus votre site sera complexe et comportera de fonctionnalités avancées, plus le coût sera élevé. De même, si vous souhaitez intégrer des technologies de pointe ou si vous avez des exigences particulières, cela peut également impacter le prix final.
N'hésitez pas à nous contacter pour demander un devis personnalisé en fonction de vos besoins spécifiques. Nos experts seront ravis de discuter avec vous de votre projet et de vous fournir une estimation précise du coût. Nous sommes là pour vous accompagner et vous aider à concrétiser votre vision en respectant vos contraintes budgétaires.
R : notre principale préoccupation n'est pas de vous vendre un simple service, mais plutôt de vous guider vers la solution optimale pour résoudre votre problématique spécifique. Avant d'entamer tout projet, nous mettons en place une démarche de conseil et d'audit approfondis afin de déterminer la meilleure stratégie digitale à adopter, en prenant en compte votre secteur d'activité ainsi que l'état actuel du marché.
Il est important de noter que cette même approche rigoureuse s'applique également au choix des technologies à utiliser. Nous accordons toujours une priorité absolue au meilleur rapport qualité-prix, afin de garantir que vous bénéficiez d'une solution technologique performante et adaptée à vos besoins spécifiques. En somme, notre engagement est de vous offrir une expertise de haut niveau et une approche sur mesure qui vous permettront d'atteindre vos objectifs avec efficacité et succès.
R : nous travaillons principalement avec des petites et moyennes entreprises (PME) situées en France et en Europe, mais également avec des entreprises à l'étranger, notamment en Suisse, en Israël, en Angleterre et aux États-Unis.
Nos solutions s'adressent à un large éventail de sociétés, allant des petites entreprises aux structures plus importantes qui cherchent à externaliser une partie de leurs activités. Nous comprenons que chaque entreprise a des besoins uniques, c'est pourquoi nous collaborons avec plusieurs agences web lorsque celles-ci font face à une surcharge de travail ou lorsqu'elles ont besoin d'une compétence spécifique qui n'est pas disponible en interne.
En travaillant en étroite collaboration avec nos partenaires, nous nous assurons de fournir des solutions sur mesure qui répondent aux besoins spécifiques de chaque entreprise. Grâce à notre réseau étendu et à notre connaissance approfondie du marché, nous sommes en mesure d'offrir des services de qualité et de garantir la satisfaction de nos clients, quelle que soit leur taille ou leur localisation géographique.
R : la création d'un site Web est un processus qui se déroule toujours à distance. Pour réaliser un site, il est nécessaire de créer des fichiers multimédias sur un ordinateur de bureau, puis de les mettre en ligne sur un autre ordinateur, peu importe s'il se trouve à seulement 500 mètres de distance ou à l'autre bout de la planète.
Grâce aux dernières avancées technologiques en matière de travail à distance, nous sommes en mesure de collaborer avec des entreprises situées aux quatre coins du globe.
Nous utilisons des outils tels que la VOIP, le partage d'écran et la vidéoconférence pour faciliter la communication et la collaboration avec nos partenaires internationaux. Ces technologies nous permettent de travailler de manière efficace et fluide, peu importe la distance qui nous sépare de nos clients. Que vous soyez à Paris, New York ou Tokyo, nous sommes prêts à travailler avec vous pour créer un site Web exceptionnel.
R : Nous mettons un point d'honneur à adopter des systèmes de gestion de contenu Open-Source, qui offrent à nos clients la flexibilité nécessaire pour éditer leurs pages, changer des images, et ajuster la mise en page aisément. Ces plateformes permettent une personnalisation poussée, vous donnant la capacité d'effectuer des modifications légères ou d'intégrer des fonctionnalités avancées en toute simplicité.
Nos solutions, basées sur ces technologies Open-Source, sont conçues pour évoluer avec vos besoins. Vous avez l'opportunité d'enrichir votre site internet avec vos propres contenus, tels que des articles d'actualité, pour qu'il reflète au mieux votre image et vos objectifs.
Cependant, il est crucial de souligner que la gestion efficace d'un site web requiert un savoir-faire professionnel. Bien que nous encouragions l'autonomie de nos clients, nous recommandons de ne pas entreprendre des modifications trop complexes qui pourraient affecter l'intégrité du site. Notre agence digitale est là pour assurer la maintenance et la pérennité de votre solution web, garantissant ainsi son bon fonctionnement continu.
Les plateformes Open-Source que nous utilisons sont dotées d'une vaste sélection de plugins et d'extensions, permettant d'élargir les fonctionnalités de votre site web à volonté. Que ce soit pour ajouter un formulaire de contact, un système de réservation ou même une boutique en ligne, tout est accessible et facile à mettre en œuvre.
Il faut cependant garder à l'esprit qu'un site web optimisé est une mécanique de haute précision, requérant expérience et expertise : nous limitons ainsi l'accès à certains éléments trop techniques de l'interface de gestion afin de prévenir toute erreur malencontreuse.
R :
Oui ! Nos solutions sont livrées avec des outils de suivi de trafic sophistiqués qui vous permettent d'avoir un aperçu détaillé de l'activité sur votre site web. De plus, toutes les données nécessaires pour suivre l'évolution de votre chiffre d'affaires et les contacts de vos clients sont disponibles.
Nous comprenons que chaque entreprise a des objectifs spécifiques, c'est pourquoi nous vous également offrons la possibilité de personnaliser votre interface de suivi statistiques en fonction de vos besoins. Vous pouvez définir vos propres indicateurs clés de performance (KPI) et suivre les métriques qui sont les plus importantes pour vous. Vous pouvez aussi définir des intervenants ciblés, afin que chaque membre de votre équipe puisse accéder aux données qui leur sont pertinentes.
Pour faciliter la gestion de vos rapports d'activité, nos solutions vous permettent d'automatiser la publication de certains rapports. Vous pouvez choisir la fréquence à laquelle vous souhaitez recevoir ces rapports et les envoyer directement à vos collègues ou clients. Cela vous permet d'économiser du temps et de rester informé de manière régulière sur l'évolution de votre activité en ligne.
Nos solutions offrent donc non seulement des outils de suivi de trafic avancés, mais aussi la possibilité de personnaliser votre interface de suivi statistiques et d'automatiser la publication de rapports d'activité. Grâce à ces fonctionnalités, vous pouvez suivre précisément l'évolution de votre chiffre d'affaires et des contacts de vos clients, tout en optimisant votre temps et en simplifiant la gestion de vos données.
R : Tout dépend de la formule pour laquelle vous optez : vous pouvez tout à fait être maître à 100 % de votre site et de son environnement informatique, en ayant un contrôle total sur chaque aspect, depuis la conception jusqu'à la maintenance. Cela vous permet d'avoir une flexibilité totale et de personnaliser votre site selon vos besoins spécifiques.
Cependant, si vous préférez vous décharger de certaines tâches techniques et consacrer votre temps à d'autres aspects de votre entreprise, vous pouvez choisir une formule d'hébergement où vous n'avez rien à gérer. Dans ce cas, des experts se chargeront de sauvegarder régulièrement votre site et d'assurer sa maintenance, afin que vous puissiez avoir l'esprit tranquille.
Quelle que soit la formule que vous choisissez, il est important de trouver un équilibre entre l'autonomie et le soutien, afin de garantir le bon fonctionnement de votre site web et de répondre aux besoins de votre entreprise.
R : Lors de la mise en place de votre boîte mail professionnelle, un technicien qualifié et expérimenté prendra contact avec vous afin de vous assister dans l'installation d'un logiciel de messagerie à distance sur votre Smartphone ou votre ordinateur de bureau. Il pourra vous guider étape par étape dans le processus d'installation afin de vous offrir une expérience fluide et sans difficultés.
Que vous utilisiez un Smartphone de dernière génération ou un ordinateur de bureau, ce logiciel de messagerie à distance vous permettra de rester connecté à votre boîte mail professionnelle où que vous soyez et à tout moment. Vous pourrez ainsi consulter et gérer vos e-mails en toute simplicité, que vous soyez en déplacement ou assis à votre bureau.
De plus, le technicien sera à votre disposition pour répondre à toutes vos questions et résoudre d'éventuels problèmes techniques. Grâce à cette assistance personnalisée, vous pourrez profiter pleinement des fonctionnalités avancées de votre boîte mail professionnelle et optimiser votre productivité au quotidien.
N'hésitez pas à contacter notre service d'assistance technique pour bénéficier d'un support professionnel et fiable lors de l'installation de votre logiciel de messagerie à distance.
R : Oui, il est important de prendre en compte que la refonte d'un site web est une tâche complexe qui nécessite une approche méticuleuse. Se lancer dans ce processus sans prendre les précautions nécessaires peut entraîner une diminution du trafic, voire sa disparition complète.
Par conséquent, il est essentiel de prévoir un budget plus conséquent pour une refonte de site, car il faut assurer la transition technique entre l'ancienne et la nouvelle version du site.
Cette étape de jonction peut être délicate, car il faut veiller à ce que toutes les fonctionnalités de l'ancien site soient préservées et intégrées de manière fluide dans la nouvelle version.
En outre, il est également important de prendre en compte les éventuels changements dans la structure et le contenu du site, afin de garantir une expérience utilisateur optimale. Une refonte de site peut également nécessiter des ajustements au niveau du référencement naturel, pour s'assurer que le nouveau site soit bien indexé par les moteurs de recherche et continue à générer du trafic organique. Il est donc essentiel de confier cette tâche à des professionnels qualifiés qui sauront garantir la réussite de votre projet.

Vous ne trouvez pas de réponse à votre question ?
Demandez à NOVA




